
korrelaatio
-
Syksyn 2025 ylioppilaskokeen arvosanojen korrelaatiomatriisi
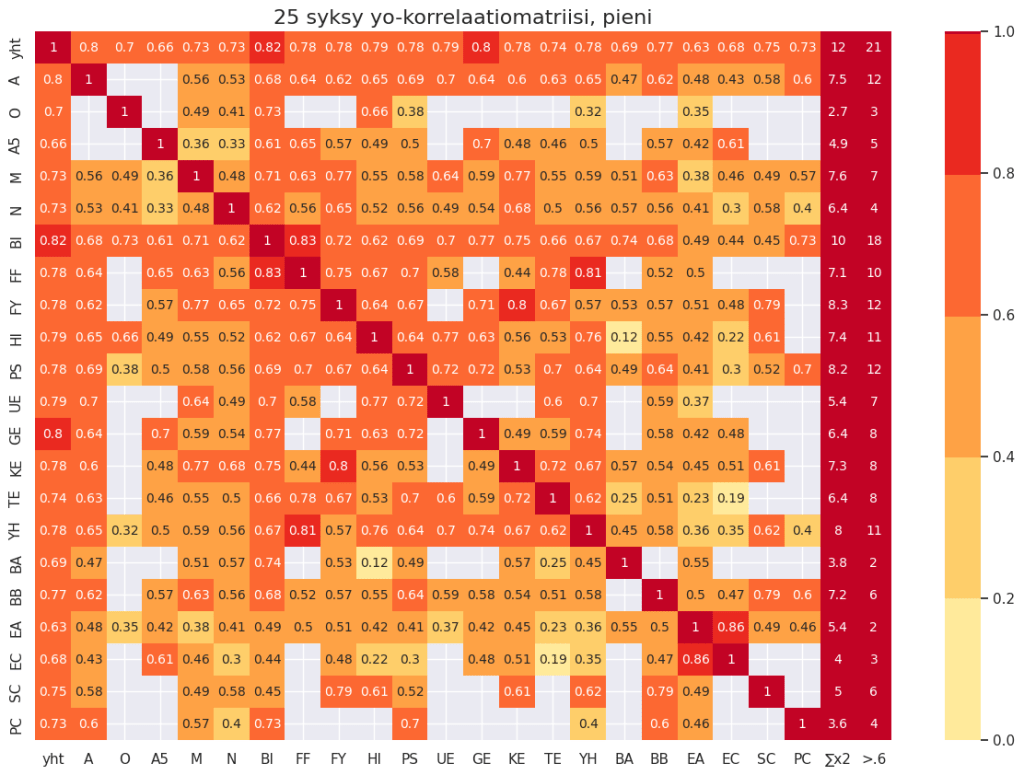
Tässä on syksyn 2025 ylioppilaiden arvosanojen korrelaatiomatriisi. Tämänkin syksyn ylioppilaiden kirjoitetuissa aineissa näkyy se, että menestyminen ylioppilaskirjoituksissa vaikuttaisi korreloivan enimmäkseen reaaliaineiden kanssa. Tämän kevyen tutkimuksen valossa biologiassa menestyminen näyttäisi ennustavan menestymistä muissa aineissa. Käytän tässä aineistona Ylioppilaslautakunnan sivulta Oppilaitoskohtaisia tunnuslukuja löytyvää tiedostoa https://tiedostot.ylioppilastutkinto.fi/ext/data/FT2025KD3001.csvTässä tiedostossa on kaikkien ylioppilaiden tulokset ja se ei päivity, eli mahdolliset korjaukset tuloksiin… Continue reading
-
Kevään 2025 ylioppilaiden arvosanojen korrelaatiomatriisi
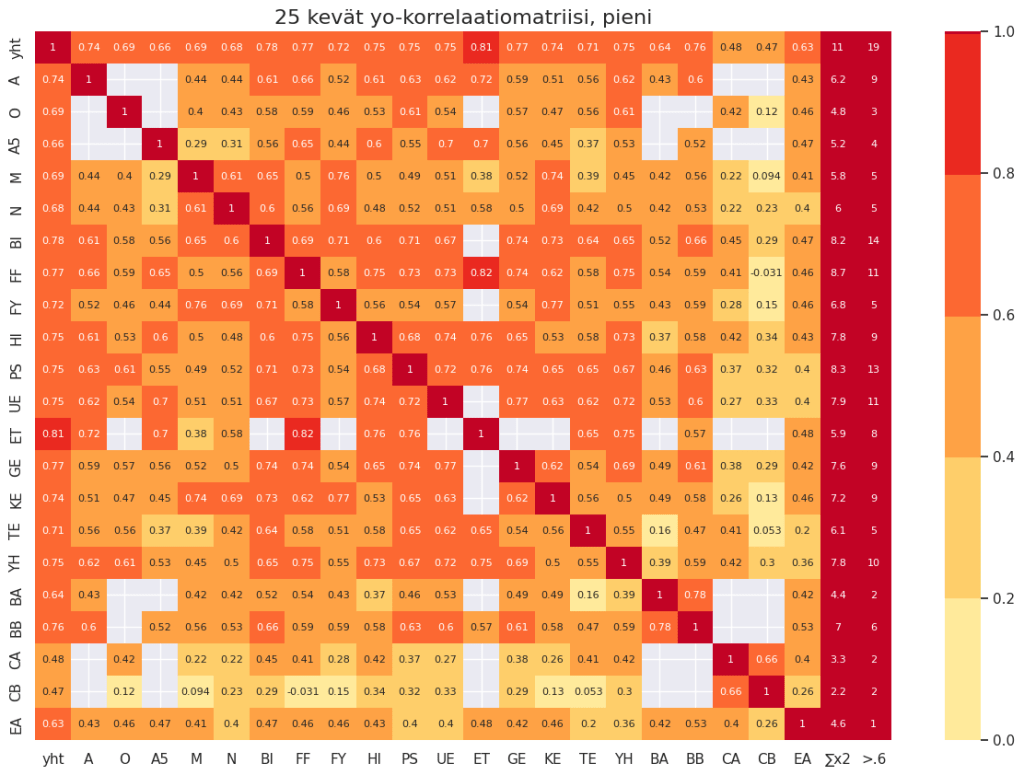
Tässä on kevään 2025 ylioppilaiden arvosanojen korrelaatiomatriisi. Tämänkin kevään ylioppilaiden kirjoitetuissa aineissa näkyy se, että menestyminen ylioppilaskirjoituksissa vaikuttaisi korreloivan enimmäkseen reaaliaineiden kanssa. Käytän tässä aineistona Ylioppilaslautakunnan sivulta Oppilaitoskohtaisia tunnuslukuja löytyvää tiedostoa https://tiedostot.ylioppilastutkinto.fi/ext/data/FT2025KD3001.csvTässä tiedostossa on kaikkien ylioppilaiden tulokset ja se ei päivity, eli mahdolliset korjaukset tuloksiin eivät näy tässä tiedostossa. korrelaatiomatriisi Keväällä 25 ylioppilaita valmistui 25486… Continue reading
-
Syksyn 2024 ylioppilaskokeen arvosanojen korrelaatiomatriisi

Tässä on syksyn 2024 ylioppilaiden aineiden arvosanojen korrelaatiomatriisi. Tämänkin syksyn ylioppilaiden kirjoitetuissa aineissa näkyy se, että menestyminen ylioppilaskirjoituksissa vaikuttaisi korreloivan enimmäkseen reaaliaineiden kanssa. Käytän tässä aineistona Ylioppilaslautakunnan sivulta Oppilaitoskohtaisia tunnuslukuja löytyvää tiedostoa https://tiedostot.ylioppilastutkinto.fi/ext/data/FT2024SD3001.csvTässä tiedostossa on kaikkien ylioppilaiden tulokset ja se ei päivity, eli mahdolliset korjaukset tuloksiin eivät näy tässä tiedostossa. korrelaatiomatriisi Syksyllä 24 ylioppilaita valmistui… Continue reading
