
tilastot
-
Lukuvuoden 2025-2026 ylioppilaiden jakaumia – tytöt sokerista ja pojat etanoista
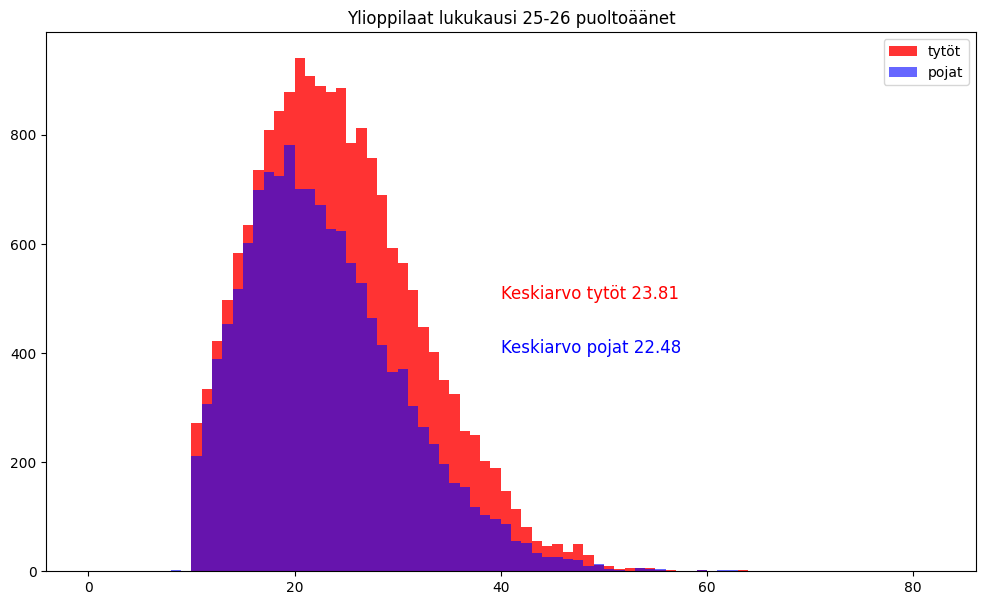
[edit. 28.5.26. Muutin otsikon alun lukuvuodeksi. 30.5.26. Korjasin Lahden Lohjaksi.] Tytöt menestyvät keskimäärin poikia paremmin ylioppilaskokeessa. Muutamassa harvassa aineessa pojilla on parempi keskiarvo kuin tytöillä. Onko syy koulussa, pojissa, kännyköissä, wokessa, pelaamisessa, opetussuunnitelmassa, opettajissa, yhteiskunnassa, vanhemmuudessa, tähtien asennossa vai missä? Tai sitten tytöt vaan ovat parempia. En tiedä. Silti jotain tarttis varmaan tehdä. Käsittelen tässä… Continue reading
-
Lukiot järjestykseen lukuvuosi 25-26
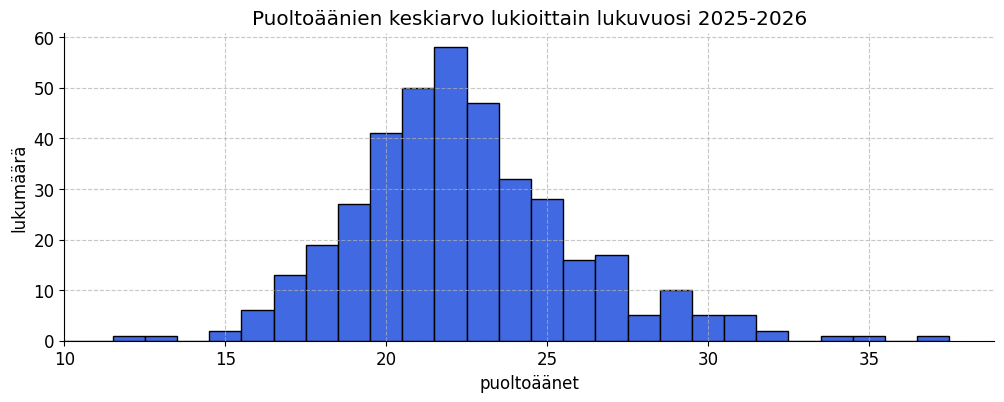
Viime joulukuussa tein ensimmäisen artikkelin tästä aiheesta. Jatkan samalla teemalla lukuvuoden 25-26 ylioppilaiden tulosten tarkastelua. YTL jakaa tiedot kunkin kirjoituskerran tuottamista ylioppilaista. Keväällä valmistuu paljon ylioppilaita (noin 28000) ja keväällä vähän (noin 3000). Niinpä on mielekkäämpää yhdistää peräkkäiset kokeet, eli tällä kertaa tutkailen syksyn 25 ja kevään 2026 ylioppilaita yhtenä joukkona. Minun mielestäni kouluja ei… Continue reading
-
Lukiot järjestykseen
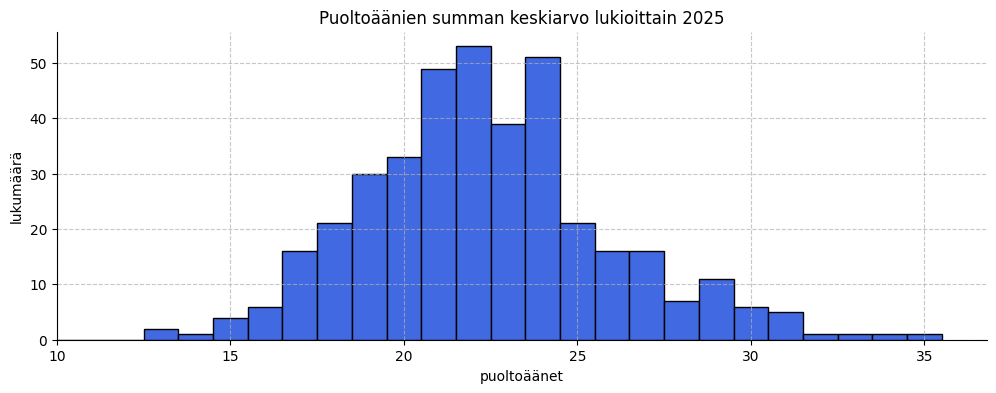
[edit. 12.12.25 Lisäsin kommentin lukioiden oppilasmääristä tietoa lukioista -lukuun. 18.1.26 Korjasin pari kirjoitusvihrettä.] Olen viime aikoina tutkiskellut Ylioppilaslautakunnan julkaisemia tilastoja ylioppilaista. Teinpä sitten pienen koodin, jonka avulla voi laittaa lukioita ”paremmuusjärjestykseen”. Laitan sanan ”paras” lainausmerkkeihin, sillä tarkoitan tässä tarinassa järjestystä, joka on mitattu puoltoäänien keskiarvon mukaan. Minun mielestäni kouluja oikeasti ei voi laittaa paremmuusjärjestykseen, kaikki… Continue reading
