
python
-
Lukuvuoden 2025-2026 ylioppilaiden jakaumia – tytöt sokerista ja pojat etanoista
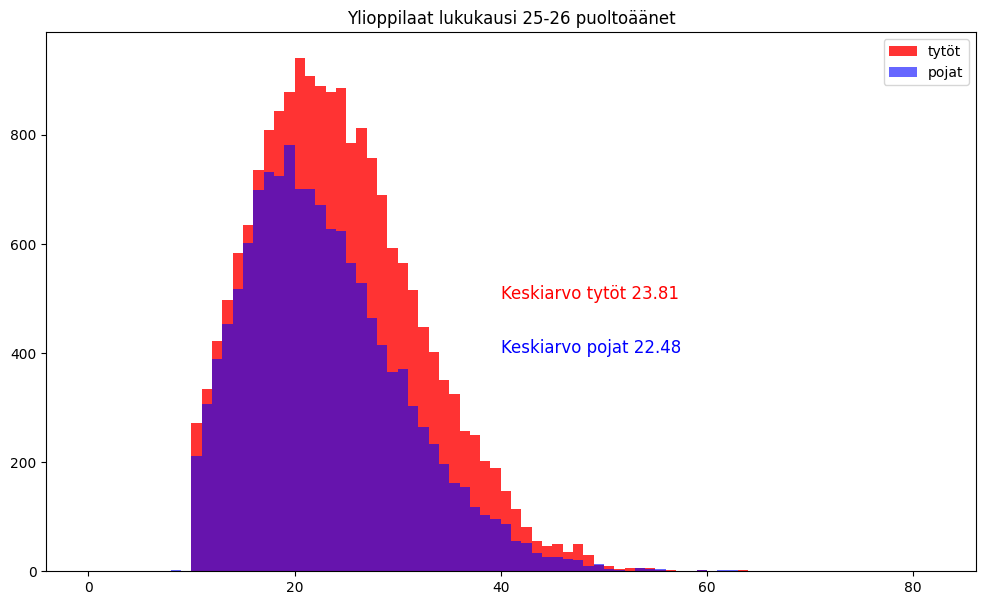
[edit. 28.5.26. Muutin otsikon alun lukuvuodeksi. 30.5.26. Korjasin Lahden Lohjaksi.] Tytöt menestyvät keskimäärin poikia paremmin ylioppilaskokeessa. Muutamassa harvassa aineessa pojilla on parempi keskiarvo kuin tytöillä. Onko syy koulussa, pojissa, kännyköissä, wokessa, pelaamisessa, opetussuunnitelmassa, opettajissa, yhteiskunnassa, vanhemmuudessa, tähtien asennossa vai missä? Tai sitten tytöt vaan ovat parempia. En tiedä. Silti jotain tarttis varmaan tehdä. Käsittelen tässä… Continue reading
-
Lukiot järjestykseen lukuvuosi 25-26
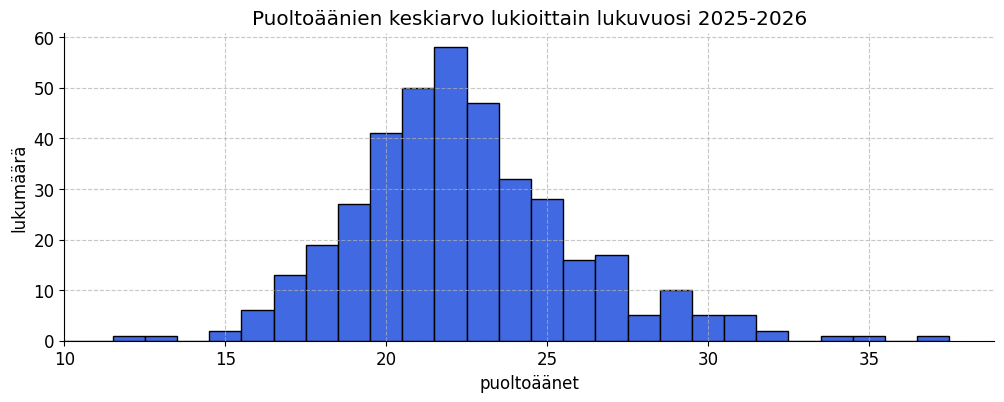
Viime joulukuussa tein ensimmäisen artikkelin tästä aiheesta. Jatkan samalla teemalla lukuvuoden 25-26 ylioppilaiden tulosten tarkastelua. YTL jakaa tiedot kunkin kirjoituskerran tuottamista ylioppilaista. Keväällä valmistuu paljon ylioppilaita (noin 28000) ja keväällä vähän (noin 3000). Niinpä on mielekkäämpää yhdistää peräkkäiset kokeet, eli tällä kertaa tutkailen syksyn 25 ja kevään 2026 ylioppilaita yhtenä joukkona. Minun mielestäni kouluja ei… Continue reading
-
Kahden kappaleen ongelman nopeusympyrätodistus
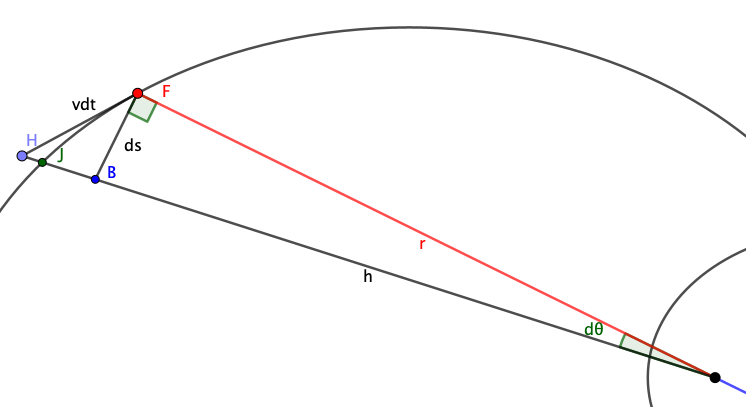
Taivaanmekaniikan Kahden kappaleen ongelmassa, kappaleiden nopeusvektorit piirtävät ympyrän (vx, vy)-koordinaatistossa, kirjoitin aiheesta edellisessä artikkelissani. Jonkun aikaa asiaa aihetta pohdiskeltuani päädyin seuraavankaltaiseen todistukseen. Ideana oli, että todistus olisi ymmärrettävä, kun on opiskellut riittävästi lukiomatematiikkaa ja fysiikkaa. Tämän yksinkertaisempaan todistukseen en pystynyt vaikka käytin apuna eri tekoälyjä. Todistuksen juoni on seuraava. Tutkitaan kappaleiden liikettä ellipsiradoilla kiinteän massakeskipisteen… Continue reading
